什么是 RPC ?
RPC (Remote Procedure Call),即远程过程调用。它允许本地计算机调用另一台远程计算机上的程序,不需要了解底层网络细节,从而使得整个过程就像本地调用一样方便。
一、RPC 调用过程
了解 RPC 调用之前,我们先来了解下本地调用是如何实现的。以 go 语言的 read 函数为例
file, err := os.Open("test.txt")
var b = make([]byte, 1024)
file.Read(b)
可以看到先通过 os 这个内置包获取一个文件句柄 fd,然后通过文件句柄 fd 去发起系统调用,进而读取文件中的数据。在远程调用的场景下,源数据存储在远程计算机,那么我们希望一次 RPC 过程应该是像本地调用一样“顺滑”的。
那么如何去实现呢?如下图所示:
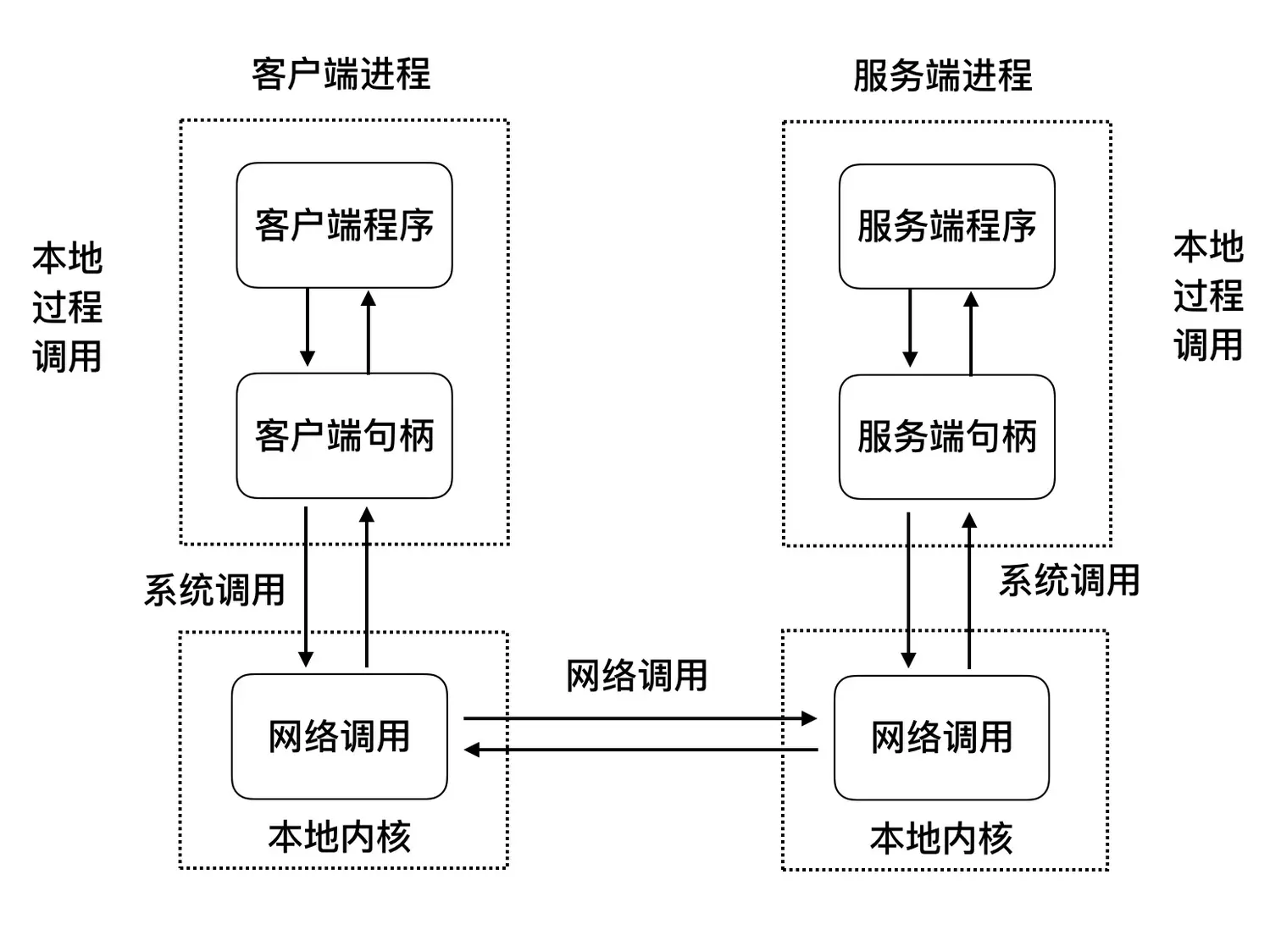
由上图可以看到,其实一次 RPC 调用,假如单独看客户端或者服务端,你会发现它和本地调用几乎一致。但是由于数据源不在本机而在远程主机,所以这里需要通过网络调用的方式,去远程主机获取数据。所以区别就在于网络调用这里。那么假如我们把网络调用的所有细节封装掉,使得其对客户端程序几乎完全无感知,这样其实就可以做到像本地调用一样“顺滑”了吗?这其实就是 RPC 需要解决的本质问题。
二、一次 RPC 调用涉及到哪些环节?
1、Socket
在计算机通信领域,socket 被翻译为“套接字”,它是计算机之间进行通信的一种约定或一种方式。通过 socket 这种约定,一台计算机可以接收其他计算机的数据,也可以向其他计算机发送数据。
2、协议
Socket 提供了计算机之前通信的能力,假如两台计算机之间建立了连接,那么如何知道彼此怎样建立连接,如何判断对方是否发送完数据,如何识别对方发送过来的数据,此时就需要一种约定,这就是协议。协议,通俗点来说,就是计算机之间进行交互的“语言”。
一说到协议,可能大家就会习惯性想到 tcp、udp、http 等这类常见性的协议。假如把计算机比喻为“人”,那么 tcp、udp、http 协议就是他们交流的“语言”,比如汉语、英语、日语等。一般来说,假如两台计算机之间能够通过一种通用的协议进行交互,比如 tcp,这种情况我们就只需要使用 tcp 就可以满足我们的需求了。但是还有些时候,我们可能会希望在一次 RPC 调用过程中,客户端和服务端可以按照我们设计的方式去进行“交流”,就好像中文、英语、日语已经满足不了我们的要求了,我们希望它们可以说“粤语”。这个时候,我们就需要自己去设计一套“语言”,这就是自定义私有协议。
3、寻址
计算机要往远程主机发消息,假如是点对点通信,客户端知道服务器的 ip,直接向这个 ip 发消息,经过路由协议,网络不丢包的情况下这里肯定是可以找到服务器,建立连接的。但是,在正常环境中,服务器一般都不止一台,它们可能同处于一个域名或者是节点名下,这个时候我们就不知道客户端的请求最终会落到哪台服务器上,也就是服务器 ip 可能是随机的。这个时候,就需要进行寻址。
寻址分为两个过程,通过域名或者是服务名去找到服务器的所有 ip,这个过程就是服务发现。在所有 ip 里面,去选择一个 ip 来接收客户端的请求,与客户端建立通信,这个过程就是负载均衡。
4、序列化和反序列化
序列化是指把对象转化为二进制流的过程,反序列化则是把二进制流转化为对象的过程。众所周知,数据在网络中传输是以二进制流的方式进行传输。我们客户端发包的时候,需要把参数对象序列化成二进制流,服务器收包后,一般会按照相同的方式去反序列化。这种序列化和反序列化的方式有很多种,比较常用的有 json、protobuf 、flattbuffers 等。
5、异常处理
上面以及把一次 RPC 调用过程中的核心环节都说到了,还有一种场景需要考虑,就是当一次 RPC 出错的时候,我们怎么知道它是在客户端、服务端、中间链路还是网络超时或者丢包呢?特别是微服务环境下,一次 RPC 可能经过十几个甚至几十个微服务的处理,这种情况下,对错误的排查难度是很高的。这个时候就要引入服务治理的概念了,服务治理是一个大命题,服务发现、负载均衡、限流、熔断、超时、重试、服务追踪等都属于服务治理的范畴,这里我们专注于一次 RPC 请求异常时的发现。这里其实可以引入链路追踪技术。这个会在后面进行具体介绍。
三、一款 RPC 框架需要解决的问题
1、开发效率问题
所有的框架都离不开这个问题,框架的初衷几乎都是为了提高开发效率,避免每次 RPC 调用都要进行重复的 socket 操作、序列化与反序列化处理、解析协议、寻址处理、异常处理。为了提高效率,我们希望 RPC 框架是简单、易用的。
2、通信效率
作为一款高性能的 RPC 框架,通信效率肯定是要求非常高的。众所周知,客户端和服务端之间的通信,以 tcp 协议为例,每次连接的创建和销毁都是消耗 cpu 资源的。假如对每次 RPC 请求都进行连接的创建和销毁,那么性能上肯定会存在很大损耗。为了避免这些损耗,一般会采取长连接的方式,同时在客户端,尽量使用连接池进行连接复用。这里后续会进行详细介绍
3、数据传输
序列化
前面说到了,数据在网络上都是以二进制流进行传输的,所以一款 RPC 框架要支持序列化和反序列化。由于不同业务采取的数据序列化方式不同,有些是 json ,有些可能是 protobuf,所以这里需要支持多种序列化方式,并且支持业务自定义。
传输效率
在传输效率上,相同的网络下,肯定是数据包越小,传输效率越高。那么如何让我们的数据包尽量小?除了序列化的方式以外,数据包本身的大小也是一个非常重要的因素。这就牵涉到协议了。文本协议的传输效率是很低的,比如http1.x 就是文本协议,它的传输效率肯定是低于 http2.0,因为 http2.0 是二进制的协议。但是二进制协议虽然传输效率高,但是它也有一个缺点,就是没有文本协议通俗易懂。所以 RPC 框架协议的设计,要综合考虑通俗易懂和传输效率两个因素。这里也会在后续框架协议的章节进行详细介绍
4、通用化
因为每个业务团队使用的技术栈不同,技术选型不同,所以要想让各个业务都能接入使用,RPC 框架的设计应该是通用化的。所以设计之初应该有两点基本要求。
- 所有的组件都是可插拔的
- 所有的组件都是支持业务自定义的。
5、服务治理
前面说到了,服务治理是一个大命题,在微服务环境下,服务治理应该是多个服务共同作用形成的一个生态圈。那这里对 RPC 框架有什么要求呢?最基础的,在框架层面需要支持业内服务治理的标准。主要是 API 层面的支持。包括但不限于服务发现、负载均衡、超时、重试、限流、熔断、分布式链路追踪等。这里我们的 RPC 框架都进行了实现,后续将会详细讲解。
小结
这一章主要讲述了 RPC 的原理和 RPC 框架需要解决的问题,带着这些问题,后续我们将会用原理介绍+代码实现的方式,一步一步进行细化讲解。