一、什么是分布式链路追踪?
现代微服务系统中,一套复杂的分布式 Web 系统中,客户端的一次请求操作,可能需要经过系统中多个模块、多个中间件、多台机器的相互协作才能完成,并且这一系列调用请求中,有些是串行处理的,有些是并发执行的,那么如何确定客户端的一次操作背后调用了哪些应用、哪些模块,经过了哪些节点,每个模块的调用先后顺序是怎样的,每个模块的性能问题如何呢?为了解决这个问题,分布式链路追踪这个概念应运而生。
分布式链路追踪技术通过在请求的源头进行标记,将这个标记顺着请求链路层层透传,从而得到整个调用链路的拓扑图,从而为分布式应用的开发者提供完整的调用链路还原、调用请求量统计、链路拓扑和应用依赖分析等工具。
二、opentracing 规范
分布式链路追踪技术的应用,最早起源于 Google 的一篇论文 Dapper, a Large-Scale Distributed Systems Tracing Infrastructure。这篇论文介绍了分布式链路追踪的原理和一些基础概念,后来这项技术得到各大厂广泛运用。比如 Twitter 的 zipkin、阿里的鹰眼、腾讯的天机阁、大众点评的 cat 等。由于不同的平台有不同的业务场景和实现标准,导致出现了各种各样的链路追踪的规范。为了解决这个问题,于是业内出现了一套统一规范 —— opentracing。opentracing 只定义分布式链路追踪的标准,并没有定义具体实现方式。下面我们对 opentracing 的规范进行简单介绍。
1、核心概念
用户
│
▼
服务 A (前端系统)
├────▶ 服务 B (中间层,处理后直接返回给 A)
│
└────▶ 服务 C (中间层)
├────▶ 服务 D (后端系统)
└────▶ 服务 E (后端系统)
我们先分析一个比较基本的服务调用链路图,如上图, A~E 分别表示五个服务,用户发起一次 X 请求到服务 A,然后 A 分别发送 RPC 请求到中间层 B 和 C,B 处理请求后返回,C 还要发起两个 RPC 请求到后端系统 D 和 E。
Trace
我们把上面一个完整的调用回路称为 trace。一个 trace 代表一个潜在的,分布式的,存在并行数据或并行执行轨迹(潜在的分布式、并行)的系统。一个 trace 可以认为是多个 span 的有向无环图(DAG)。
在一个完整调用回路中,一次请求需要经过多个系统处理完成,并且追踪系统像是内嵌在 RPC 调用链上的树形结构,然而,我们的核心数据模型不只局限于特定的 RPC 框架,我们还能追踪其他行为,例如外界的 HTTP 请求,和外部对 Kafka 服务器的调用等。从形式上看,针对 trace 我们使用一个树形结构来记录请求之间的关系(父子关系、先后顺序等)。
Span
一个 span 代表系统中具有开始时间和执行时长的逻辑运行单元。span 之间通过嵌套或者顺序排列建立逻辑因果关系。
拿上图来说,一个 tracer 过程中,A、B、C、D、E 各 span 的关系可能如下:
[Span A] ←←←(the root span)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C 是 Span A 的孩子节点, ChildOf)
|
+---+-------+
| |
[Span D] [Span E] >>> [其他平级 Span]
opentracing 规范约定,span 之间有两种关系,一种是 ChildOf ,也就是父子关系,如上图的 A 和 B、C ,C 和 D、E 就是父子关系。另一种是 FollowsFrom,这是一种平级关系 ,例如上图中的 B 和 C,E 和 F 等。
SpanContext
每个 Span 必须提供访问的 SpanContext,SpanContext 一般用来保存需要传递到下游的服务的一些信息。比如 TraceID、SpanID、ParentSpanID 等,SpanContext 还可以用来封装 Baggage (存储在 SpanContext 中的一个键值对集合)
更多的概念可以参考:opentracing 英文版, opentracing 翻译版
三、技术选型
社区内支持 opentracing 规范的比较著名的开源项目有 jaeger、zipkin、appdash 、cat 等。
- jaeger: go 语言开发,入手较为困难,系统侵入性一般,数据维度比较丰富,但是入手比较困难。
- appdash:go 语言开发,适合于开发小型的 trace 系统,主要依赖内存,不适合大规模使用。
- zipkin,java 语言开发,github 很活跃,系统倾入性强,扩展性高,也有很多大厂使用
- cat,java 语言开发,github 不活跃,已不太更新了。
由于我们的框架使用 go 语言实现,所以我们也主要考虑同样使用 go 开发的 jaeger 和 appdash,由于 appdash 比较依赖内存,不适合大规模使用,所以我们最终选择了 jaeger。
四、jaeger 简单介绍
jaeger 是遵循 opentracing 规范的,所以上面介绍的 opentracing 的相关核心概念 jaeger 中也同样适用,哲理就不赘述了。jaeger 的一些使用方法可以详细参考官方文档 jaeger
这里我们简单介绍下 jaeger 的架构,如下图:
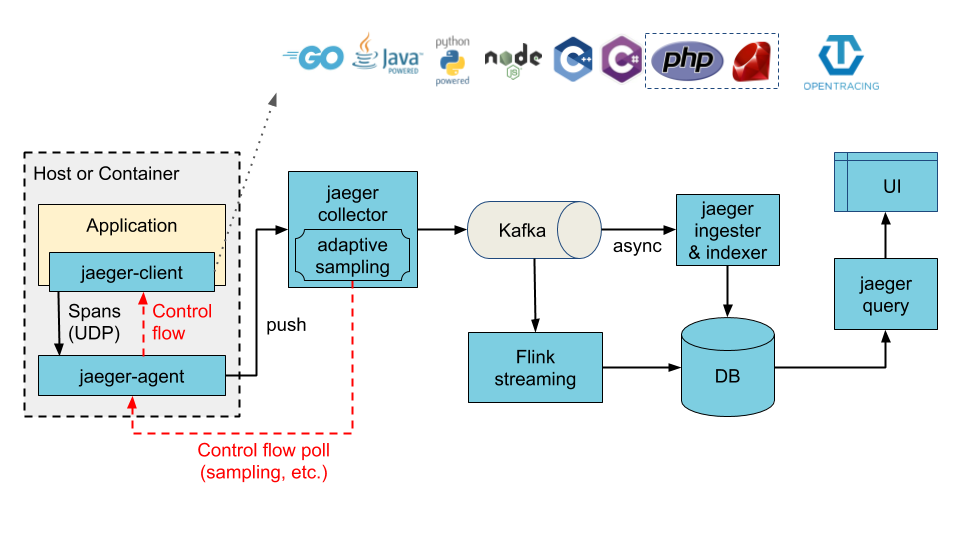
client 将 Span 数据上报到 agent,通过 agent 将数据发送到 collector 进行收集。collector 收集 agent 上报的数据之后,通过 kafka 消息队列,通过 flink 集群将数据汇总到 DB,UI 通过查询 DB 中的数据来进行链路图的展示。
jaeger demo
jaeger 官方提供了一个集成了所有服务的 docker 镜像,运行:
docker run -d --name jaeger \
-e COLLECTOR_ZIPKIN_HTTP_PORT=9411 \
-p 5775:5775/udp \
-p 6831:6831/udp \
-p 6832:6832/udp \
-p 5778:5778 \
-p 16686:16686 \
-p 14268:14268 \
-p 14250:14250 \
-p 9411:9411 \
jaegertracing/all-in-one:1.17
然后在浏览器访问 http://localhost:16686 即可看到 jaeger 的 UI,如下:
小结
本章主要介绍了分布式链路追踪的原理、opentracing 的核心概念和 jaeger 的简单实用,下一章我们将会介绍代码实现