上一章介绍了使用 pprof 工具进行框架的性能测试,本章来继续介绍一下如何通过火焰图分析框架的性能瓶颈,并进行相应的性能优化。
一、压测环境
压测的前提是有一台压测机器,我们的压测环境为:
- CPU : Intel(R) Xeon(R) Gold 61xx CPU @2.44GHz
- CPU cores : 8
- Memory : 16G
- Disk : 540G
优化前的性能是:
took 13267 ms for 1000000 requests
sent requests : 1000000
received requests : 1000000
received requests succ : 1000000
received requests fail : 0
throughput (TPS) : 75374
二、分析火焰图
优化前的火焰图如下:
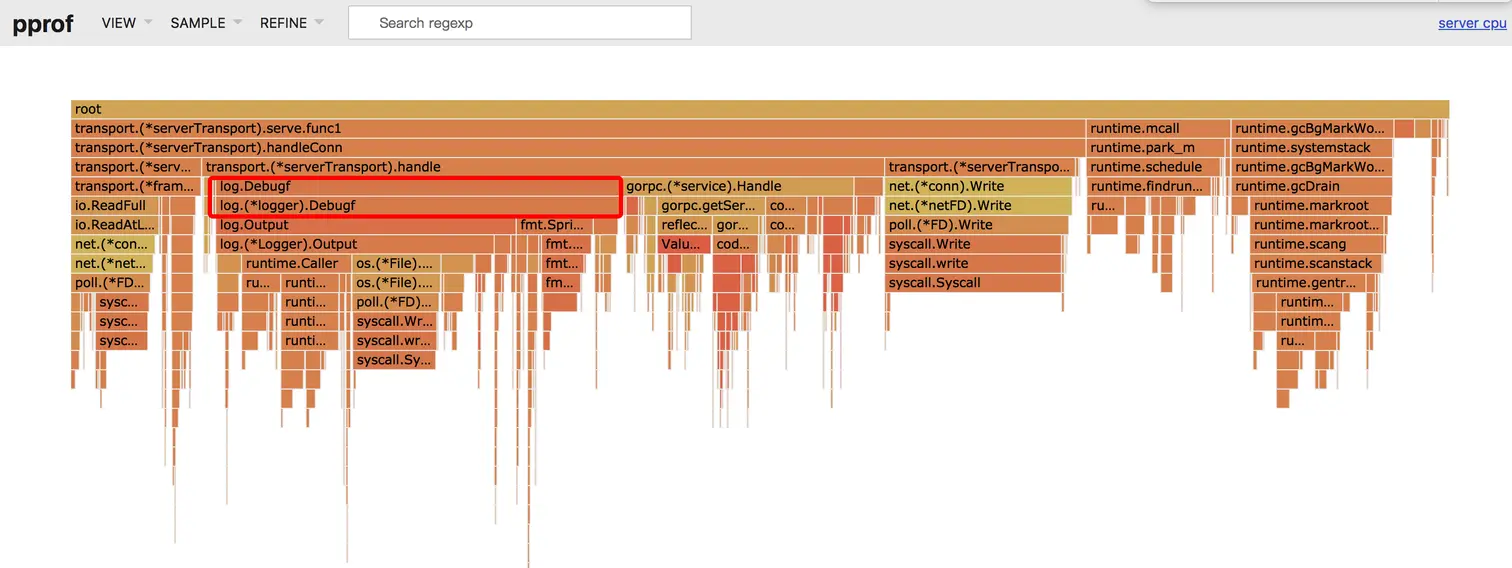
火焰图非常清楚地展示了框架的整个调用链路。我们阅读火焰图时只需要从上往下看,调用的层次是从上往下层层调用。比如 transport.(serverTransport).handleConn 这个函数就调用了 transport.(serverTransport).read 和 transport.(*serverTransport).handle 这两个函数。
我们可以比较清晰地看到,log.Debugf 这个函数耗时非常大,原来是我们在代码中调试时不小心加上了一行日志。
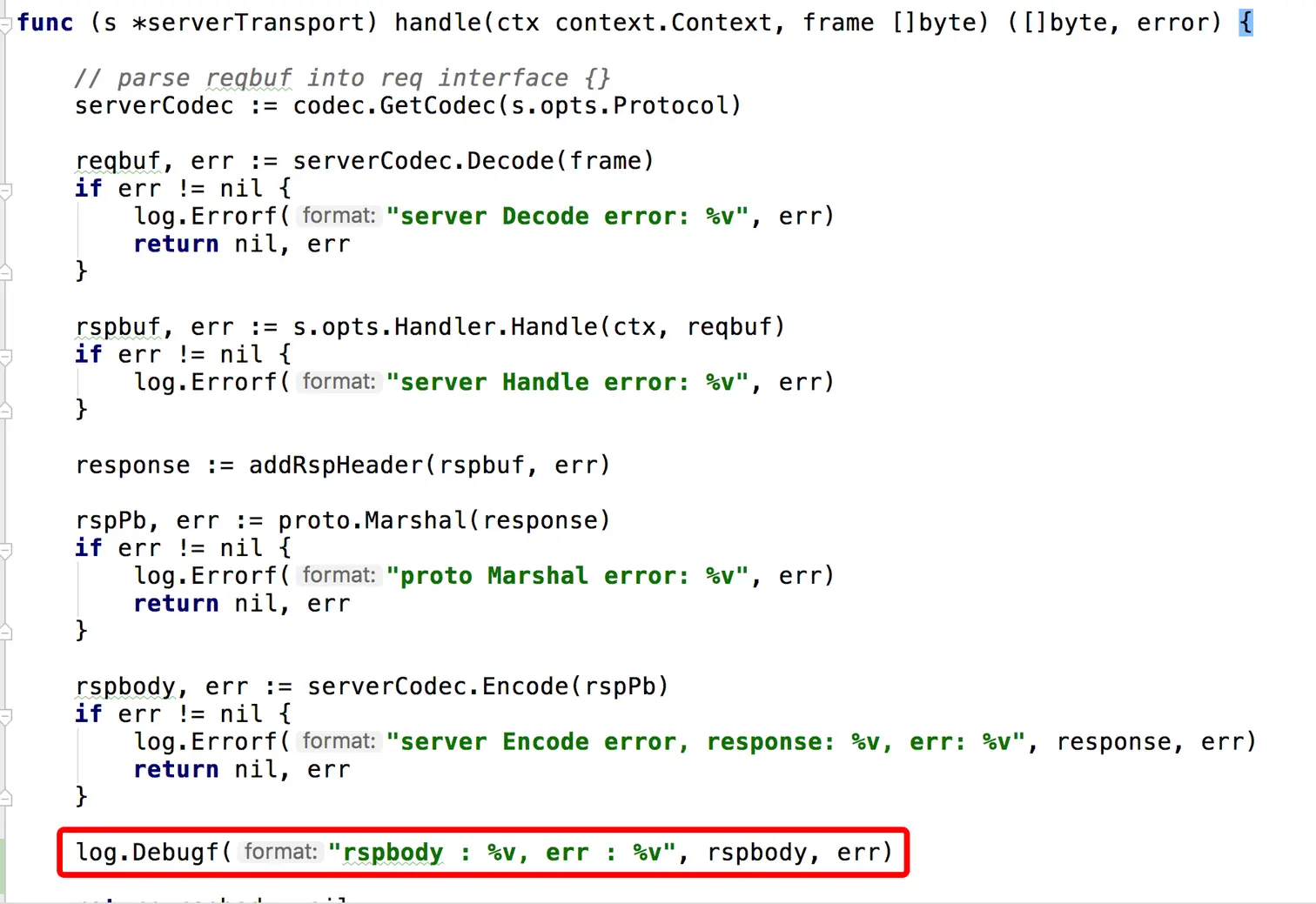
把这行日志去掉,继续测试,发现性能果然有显著提升,如下:
took 30574 ms for 5000000 requestssent requests : 5000000
received requests : 5000000
received requests succ : 5000000
received requests fail : 0
throughput (TPS) : 163537
说明打日志是非常消耗性能的。这也是我们线上的业务一般来说不会打 debug 日志,只会打少量业务失败的 error 日志的原因之一。
三、性能优化过程
ok,刚刚的日志问题只是一个小插曲,让大家简单了解怎么去看火焰图,接下来我们来看看如何继续去提升框架的性能。
去掉 log.Debugf 日志打印后,继续分析火焰图,按道理,一个 server 的性能应该主要是消耗在读写上,读写的占比越高,server 的性能就越高。我们看到耗时占比很高的地方是 transport.(serverTransport).handle 这个函数,继续分析发现是 gorpc.getServiceMethods.func1 这个函数里面主要有两步操作比较耗时,第一步是 reflect.Value.Call 反射调用 ,第二步是 codec.(MsgpackSerialization).Unmarshal 反序列化操作。
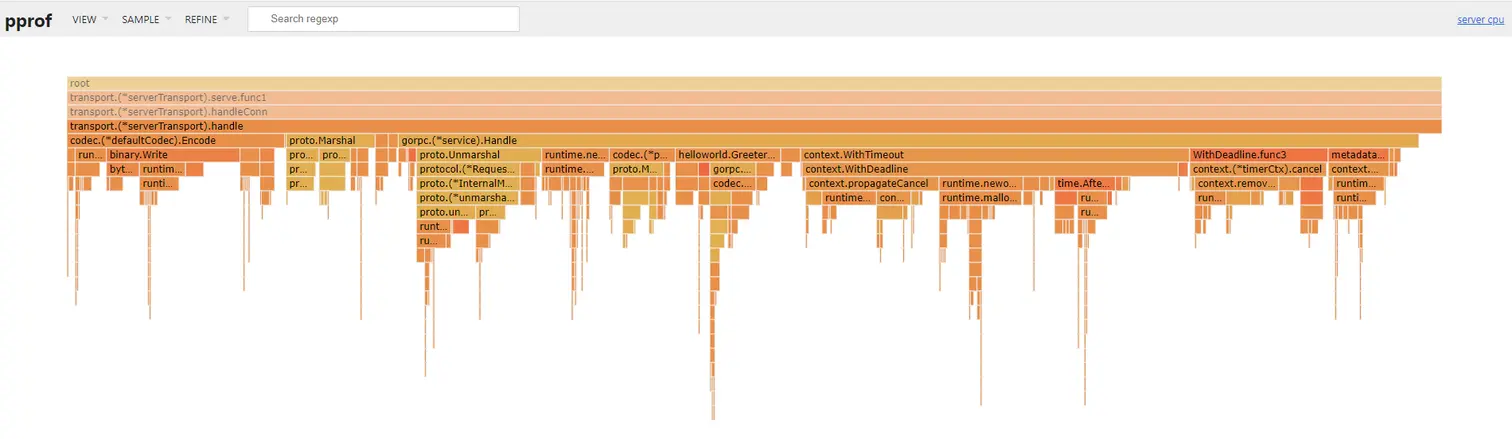
反序列化操作的耗时是无法避免的,之前我们分析过各种反序列化的库,发现 msgpack 这个库的反序列化性能是比较靠前的。于是这里我们主要的突破点就放在反射操作上。尝试一下用代码生成的方式,提前生成调用代码,避免反射操作运行时动态去探测数据类型造成的性能消耗。
这里我们在 gorpc-benchmark 里面新建一个 codegen 目录,这个目录里面的 server 和 client 的桩代码都是使用代码生成的方式实现。使用 codegen 下的 client 和 server 测试,结果如下:
took 26011 ms for 5000000 requests
sent requests : 5000000
received requests : 5000000
received requests succ : 5000000
received requests fail : 0
throughput (TPS) : 192226
这就很厉害了,直接提升了近 3w,达到了 19 w,此时的火焰图如下:
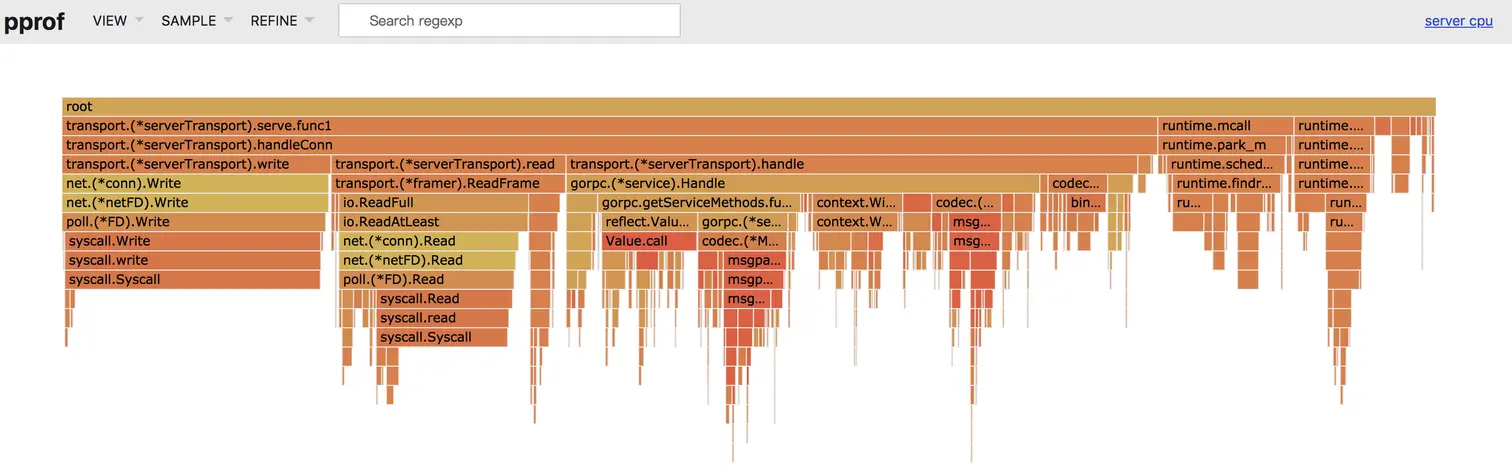
再仔细分析一下火焰图,发现在 proto 序列化和反序列化的过程中有不少耗时,此时 proto 序列化和反序列化的代码如下:
type pbSerialization struct {}
func (d *pbSerialization) Marshal(v interface{}) ([]byte, error) {
if v == nil {
return nil, errors.New("marshal nil interface{}")
}
if val, ok := v.(proto.Message); ok {
return proto.Marshal(val)
}
return []byte(""), errors.New("data type not proto.Message")
}
func (d *pbSerialization) Unmarshal(data []byte, v interface{}) error {
if data == nil || len(data) == 0 {
return errors.New("unmarshal nil or empty bytes")
}
if val, ok := v.(proto.Message); ok {
return proto.Unmarshal(data, val)
}
return errors.New("data type not proto.Message")
}
仔细阅读 proto.Marshal 和 Unmarshal 的源码发现,它是使用反射机制去进行序列化和反序列化的。前面说到了反射会影响系统的性能。这里我们就想能不能有个办法去减少反射调用的次数,这里直接使用了 proto.Buffer 对象来进行优化。从官方的介绍中可以知道它能够被用来减少内存使用,我们可以通过 Buffer 类来减少每次序列化和反序列化的内存消耗和反射次数。它的定义如下:
// A Buffer is a buffer manager for marshaling and unmarshaling
// protocol buffers. It may be reused between invocations to
// reduce memory usage. It is not necessary to use a Buffer;
// the global functions Marshal and Unmarshal create a
// temporary Buffer and are fine for most applications.
type Buffer struct {
buf []byte // encode/decode byte stream
index int // read point
deterministic bool
}
这里我们用了一个对象池 bufferPool 来减少内存的频繁分配导致的 gc,如下:
var bufferPool = &sync.Pool{
New : func() interface {} {
return &cachedBuffer {
Buffer : proto.Buffer{},
lastMarshaledSize : 16,
}
},
}
type cachedBuffer struct {
proto.Buffer
lastMarshaledSize uint32
}
序列化和反序列化优化后代码如下:
type pbSerialization struct {}
func (d *pbSerialization) MarshalV2(v interface{}) ([]byte, error) {
if v == nil {
return nil, errors.New("marshal nil interface{}")
}
if pm, ok := v.(proto.Marshaler); ok {
// 可以 marshal 自身,无需 buffer
return pm.Marshal()
}
buffer := bufferPool.Get().(*cachedBuffer)
protoMsg := v.(proto.Message)
lastMarshaledSize := make([]byte, 0, buffer.lastMarshaledSize)
buffer.SetBuf(lastMarshaledSize)
buffer.Reset()
if err := buffer.Marshal(protoMsg); err != nil {
return nil, err
}
data := buffer.Bytes()
buffer.lastMarshaledSize = upperLimit(len(data))
buffer.SetBuf(nil)
bufferPool.Put(buffer)
return data, nil
}
func (d *pbSerialization) UnmarshalV2(data []byte, v interface{}) error {
if data == nil || len(data) == 0 {
return errors.New("unmarshal nil or empty bytes")
}
protoMsg := v.(proto.Message)
protoMsg.Reset()
if pu, ok := protoMsg.(proto.Unmarshaler); ok {
// 可以 unmarshal 自身,无需 buffer
return pu.Unmarshal(data)
}
buffer := bufferPool.Get().(*cachedBuffer)
buffer.SetBuf(data)
err := buffer.Unmarshal(protoMsg)
buffer.SetBuf(nil)
bufferPool.Put(buffer)
return err
}
此时,我们再进行性能测试,结果如下:
took 4624 ms for 1000000 requests
sent requests : 1000000
received requests : 1000000
received requests succ : 1000000
received requests fail : 0
throughput (TPS) : 216262
可以看到,这里大约有 2w 左右的提升。
四、对标 grpc
经过上面的简单优化,我们发现框架的性能提升到了 21 w 左右,同时对 grpc 进行简单的性能测试,发现性能为 6w 左右,性能数据如下:
took 17169 ms for 1000000 requests
sent requests : 1000000
received requests : 1000000
received requests succ : 1000000
received requests fail : 0
throughput (TPS) : 58244
详情可以参考:Performance
单从性能上来说,我们的 gorpc 框架性能达到了 grpc-go 的 3.5 倍。我们的性能优化先到这里。
小结
本章节主要介绍了框架的性能优化过程,性能优化是一条很漫长的旅途,本章节只是抛砖引玉,重点是如何去分析系统性能瓶颈,如何看火焰图等。路漫漫其修远兮,这里做了一些简单的入门级介绍。