一、序列化与反序列化
在计算机网络中,数据都是以二进制形式进行传输的。将对象转换成可以传输的二进制数据的过程叫做序列化。将二进制的数据转换成对象的过程叫做反序列化。
go 原生序列化与反序列化
go 语言中提供了一个 encoding/binary 包实现了简单的数字(固定长度的数字类型或者只包含定长值的结构体或数组)与字节流的转换和 varint 的编解码。varint 也是一种编解码方式,google 的 protobuffer 也大量使用了 varint ,这里不详细介绍,有兴趣的同学可以自行 google。我们重点来看看 go binary 包提供的数据和 []byte 的转换能力,核心 api 如下:
// r - 实现了 io.Reader 接口的可以被读取的数据源,如 net.Conn
// order - 特殊字节序,binary 中提供了大端序和小端序
// data - 需要被解码的数据
func Read(r io.Reader, order ByteOrder, data interface{}) error
// w - 实现了 io.Writer 接口的可以被写入数据源,如 net.Conn
// order - 特殊字节序,binary 中提供了大端序和小端序
// data - 需要被编码的数据
func Write(w io.Writer, order ByteOrder, data interface{}) error
它提供了具有读写能力的 Read 和 Write 接口。下面是一个简单的使用 binary 进行读写的 example
func main() {
var pi float64
b := []byte{0x18,0x2d,0x44,0x54,0xfb,0x21,0x09,0x40}
buf := bytes.NewBuffer(b)
err := binary.Read(buf, binary.BigEndian, &pi)
if err != nil {
log.Fatalln(err)
}
fmt.Println("pi = ", pi)
buf = new(bytes.Buffer)
pi = math.Pi
err = binary.Write(buf, binary.BigEndian, pi)
if err != nil {
log.Fatalln(err)
}
fmt.Println("math.Pi bytes : ", buf.Bytes())
}
二、序列化方案的选型
之前介绍 rpc 原理的时候,介绍过一些序列化方案的选型,这里再展开说一下。每种序列化库的性能数据如下:(引用网上的数据)
benchmark _name iter time/iter alloc bytes/iter allocs/iter
-------------------------------------------------------------------------------------------------------------------------
BenchmarkMarshalByJson-4 1000000 1795 ns/op 376 B/op 4 allocs/op
BenchmarkUnmarshalByJson-4 500000 3927 ns/op 296 B/op 9 allocs/op
BenchmarkMarshalByXml-4 200000 8216 ns/op 4801 B/op 12 allocs/op
BenchmarkUnmarshalByXml-4 50000 26284 ns/op 2807 B/op 67 allocs/op
BenchmarkMarshalByBson-4 500000 3258 ns/op 1248 B/op 14 allocs/op
BenchmarkUnmarshalByBson-4 1000000 1433 ns/op 272 B/op 7 allocs/op
BenchmarkMarshalByMsgp-4 5000000 259 ns/op 80 B/op 1 allocs/op
BenchmarkUnmarshalByMsgp-4 3000000 466 ns/op 32 B/op 5 allocs/op
BenchmarkMarshalByProtoBuf-4 2000000 955 ns/op 328 B/op 5 allocs/op
BenchmarkUnmarshalByProtoBuf-4 1000000 1571 ns/op 400 B/op 11 allocs/op
BenchmarkMarshalByGogoProtoBuf-4 10000000 224 ns/op 48 B/op 1 allocs/op
BenchmarkUnmarshalByGogoProtoBuf-4 2000000 828 ns/op 144 B/op 8 allocs/op
BenchmarkMarshalByFlatBuffers-4 3000000 626 ns/op 16 B/op 1 allocs/op
BenchmarkUnmarshalByFlatBuffers-4 100000000 10.4 ns/op 0 B/op 0 allocs/op
BenchmarkUnmarshalByFlatBuffers_withFields-4 3000000 493 ns/op 32 B/op 5 allocs/op
BenchmarkMarshalByThrift-4 2000000 840 ns/op 64 B/op 1 allocs/op
BenchmarkUnmarshalByThrift-4 1000000 1575 ns/op 96 B/op 6 allocs/op
BenchmarkMarshalByAvro-4 1000000 1330 ns/op 133 B/op 7 allocs/op
BenchmarkUnmarshalByAvro-4 200000 7036 ns/op 1680 B/op 63 allocs/op
BenchmarkMarshalByGencode-4 20000000 66.2 ns/op 0 B/op 0 allocs/op
BenchmarkUnmarshalByGencode-4 5000000 258 ns/op 32 B/op 5 allocs/op
可以看到,比较常用的库里面,gogoprotobuf > msgpack > flatbuffers > thrift > protobuf > json
之前我们说过,我们的框架有两种调用方式,一种是使用反射、一种是使用代码生成。
假如使用反射的话,我们发现只有 msgpack 、json 能够对原生的 go struct 进行序列化。由于 msgpack 性能远高于 json,所以这里我们就直接选择了 msgpack。
假如使用代码生成的调用方式,这里有 gogoprotobuf、flatbuffers、thrift、protobuf 四种方案可以选。从性能上讲,四种序列化库其实性能都已经比较优秀了,但是其中 gogoprotobuf 的序列化性能是最好的。由于目前使用最广泛的还是 protobuf,考虑到 gogoprotobuf 和 protobuf 不兼容,这里选择了比较广泛的通用化方案 protobuf,当然,后续我们也支持 gogoprotobuf 序列化方式的实现,业务可以自己选择用哪种方式进行序列化。
三、何时进行序列化与反序列化
讲到序列化这里,可能有些朋友会把序列化和编解码搞混。把对象转为二进制数据不是编码的过程吗?这里编解码和序列化/反序列化的关系是什么呢?下面一张图告诉你。
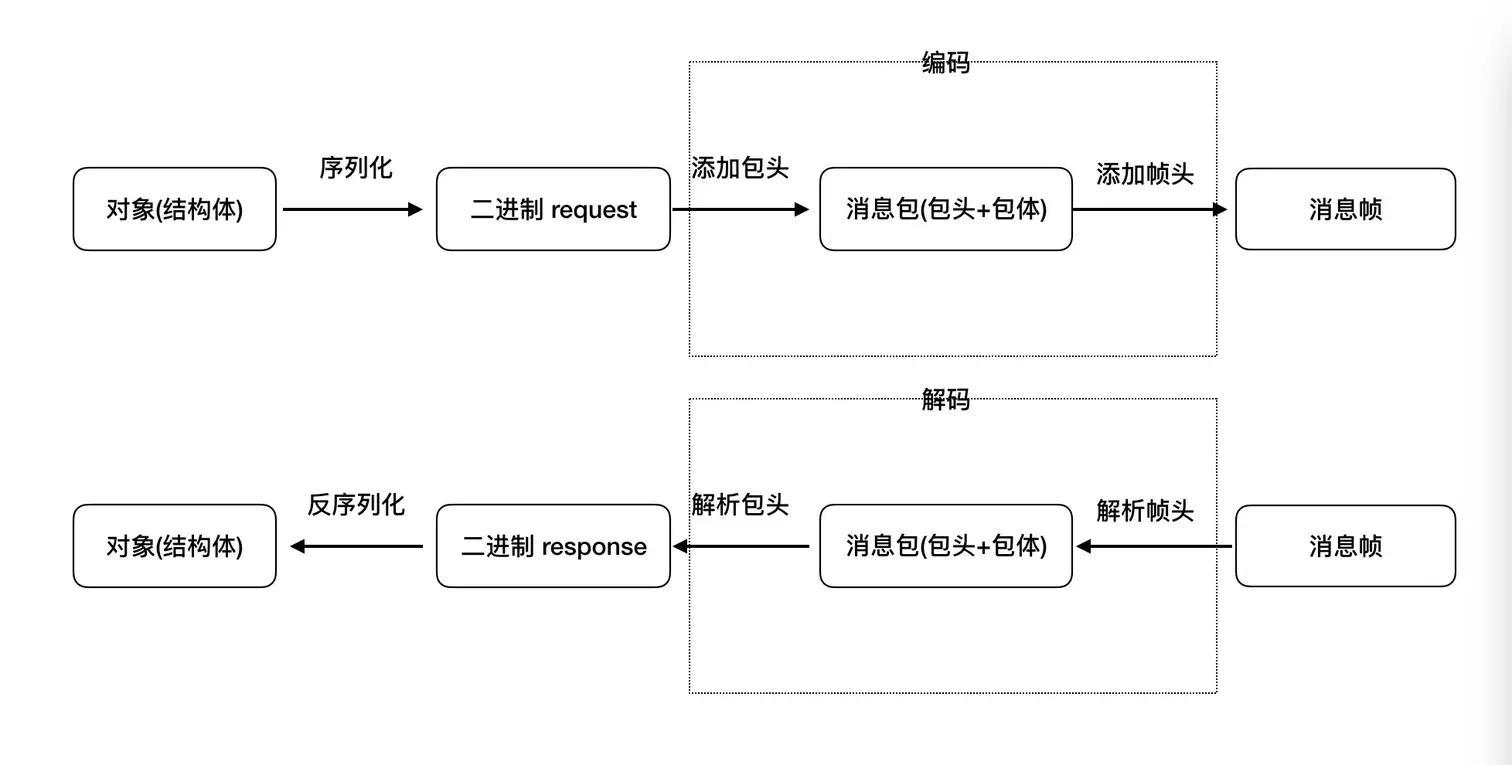
所以编码是在对象序列化之后,将对象的二进制数据进行编码,加上包头、帧头使其成为一个完整的消息帧。反序列化是在对象解码之后,从一个完整的消息帧解析出帧头、包头,得到对象的二进制数据,然后再进行反序列化得到一个对象。
四、序列化和反序列化实现
这里首先定义一个 Serialization 的接口,用与序列化的通用实现标准,所有的序列化组件都需要实现这两个方法。
type Serialization interface {
Marshal(interface{})([]byte, error)
Unmarshal([]byte, interface{}) error
}
、msgpack 序列化实现
msgpack 的序列化与反序列化直接使用 github 上第三方包实现 msgpack
这里的实现比较简单,只需要实现 Marshal、Unmarshal 两个方法即可
type MsgpackSerialization struct {}
func (c *MsgpackSerialization) Marshal(v interface{}) ([]byte, error) {
var buf bytes.Buffer
encoder := msgpack.NewEncoder(&buf)
err := encoder.Encode(v)
return buf.Bytes(), err
}
func (c *MsgpackSerialization) Unmarshal(data []byte, v interface{}) error {
decoder := msgpack.NewDecoder(bytes.NewReader(data))
err := decoder.Decode(v)
return err
}
2、protobuf 序列化实现
protobuf 序列化与反序列化这里,为了避免对象的频繁创建于销毁,使用了一个内存池。如下:
var bufferPool = &sync.Pool{
New : func() interface {} {
return &cachedBuffer {
Buffer : proto.Buffer{},
lastMarshaledSize : 16,
}
},
}
type cachedBuffer struct {
proto.Buffer
lastMarshaledSize uint32
}
func (d *pbSerialization) Marshal(v interface{}) ([]byte, error) {
if pm, ok := v.(proto.Marshaler); ok {
// 可以 marshal 自身,无需 buffer
return pm.Marshal()
}
buffer := bufferPool.Get().(*cachedBuffer)
protoMsg := v.(proto.Message)
lastMarshaledSize := make([]byte, 0, buffer.lastMarshaledSize)
buffer.SetBuf(lastMarshaledSize)
buffer.Reset()
if err := buffer.Marshal(protoMsg); err != nil {
return nil, err
}
data := buffer.Bytes()
buffer.lastMarshaledSize = upperLimit(len(data))
return data, nil
}
func (d *pbSerialization) Unmarshal(data []byte, v interface{}) error {
protoMsg := v.(proto.Message)
protoMsg.Reset()
if pu, ok := protoMsg.(proto.Unmarshaler); ok {
// 可以 unmarshal 自身,无需 buffer
return pu.Unmarshal(data)
}
buffer := bufferPool.Get().(*cachedBuffer)
buffer.SetBuf(data)
err := buffer.Unmarshal(protoMsg)
buffer.SetBuf(nil)
bufferPool.Put(buffer)
return err
}
小结
本章主要介绍了 go 原生序列化的实现,序列化的选型,序列化与编解码的区别。同时提供了 msgpack 和 protobuf 两种方式的序列化和反序列化实现。